{kind=link}
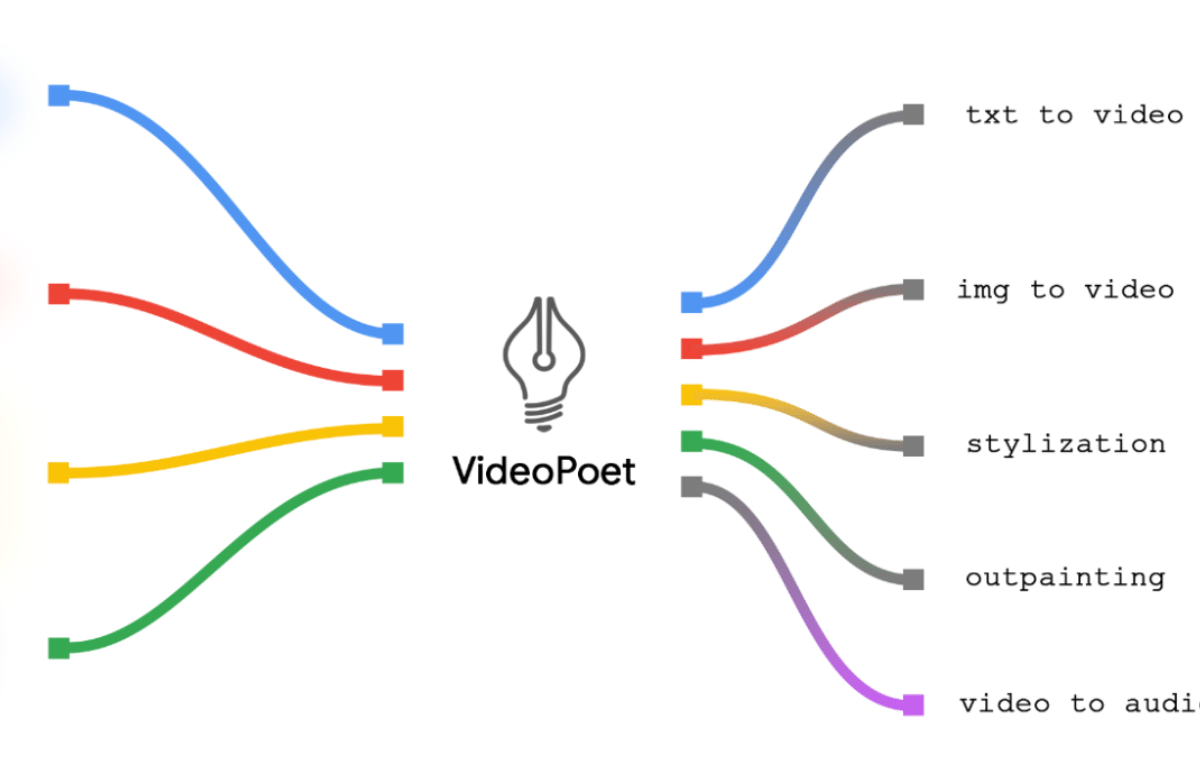
كشفت جوجل عن النسخة الجديدة من نموذجها اللغوي الضخم لإنتاج الفيديو المعروف باسم VideoPoet، وهو مصمم لأداء مجموعة متنوعة من المهام، بما في ذلك تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو، وتحويل الفيديو إلى صوت.
VideoPoet يعمل على حل تحدي إنشاء حركات متناسقة ومتماسكة في مقاطع الفيديو، وهذا يعتبر تحديًّا في تقنيات إنتاج الفيديو الحالية.
يتميز هذا النموذج الجديد بتكامل القدرات المتعددة لتوليد الفيديو في إطار نموذج لغوي كبير واحد، بالمقارنة مع النماذج الحالية التي تعتمد على نهج تجزئة القدرات.
يتم استعمال النموذج بأساليب متنوعة وهو مدرب باستخدام عدة رموز مميزة، مثل MAGVIT V2 للفيديو والصور و SoundStream للصوت.
باستخدام هذه الوظيفة، يمكن لـ VideoPoet أداء مجموعة من المهام المتنوعة؛ مثل تحريك الصور وتعديل وتصميم مقاطع الفيديو استنادًا إلى المعطيات المدخلة من النص.
تبرز VideoPoet كتطور كبير في المشهد المتطور لتكنولوجيا توليد الفيديو باستخدام الذكاء الاصطناعي، حيث يتميز بنفسه عن النماذج الحالية مثل Imagen Video و RunwayML و Stable Video Diffusion و Pika و Animate Anywhere، من خلال قدراته المحسنة في دقة النص وإيقاع الحركة.
يتميز هذا النموذج الجديد بتفوقه على النماذج المماثلة من خلال اتباع المطالبات النصية بشكل دقيق وإنتاج مقاطع فيديو ممتعة بحركات جاذبة.
تبرز النموذج الجديد لغوغل في إنتاج المحتوى بشكل أفضل من خلال استخدام أدنى قدر من المدخلات، مثل رسالة نصية واحدة أو صورة واحدة، دون الحاجة لتدريب محدد على هذا المحتوى.
يقدم تطبيق VideoPoet درجة عالية من الدقة في تحويل المحتوى الكتابي إلى فيديو، بعكس التطبيقات الأخرى التي قد تعاني من صعوبة في إنشاء حركات متناغمة كبيرة، مما يعزز تجربة المستخدم.
وتواجه النماذج الأخرى في كثير من الأحيان تحديات في إنتاج حركات كبيرة متماسكة خالية من العيوب، في حين يظهر النموذج الجديد لجوجل تحسنًا ملحوظًا في هذا المجال، مما ينجم عنه إنتاج مقاطع فيديو ديناميكية وسلسة.